Git ed i sistemi per il controllo di versione
Git è un sistema per il controllo di versione distribuito. Inizialmente sviluppato da Linus Torvalds per gestire lo sviluppo del kernel Linux, oggi è utilizzato dalle aziende informatiche di tutto il mondo.
I progetti pubblicamente esposti dagli sviluppatori sui vari servizi di controllo di versione rappresentano una sorta di “Instagram”, utilizzato per condividere non foto e video, ma i propri lavori: libri, personaggi 2D e 3D, animazioni, stili grafici e soprattutto il codice sorgente dei software in corso di sviluppo.
Installazione di git
Git è facilmente installabile attraverso i package manager. Di seguito sono elencati i comandi, relativi ai package manager più conosciuti, necessari per installare Git. Si presuppone, ovviamente, che l’utente abbia installato il package manager a cui il comando si riferisce.
Su package manager “choco” di Windows:
choco install git
Su package manager “apt” di Linux (Debian based):
sudo apt install git-all
Su package manager “dnf” di Linux (RedHat based):
sudo dnf install git-all
Su package manager “homebrew”:
brew install git
Se non si dispone di un package manager, si può effettuare il download del pacchetto di installazione dal sito https://git-scm.com/.
Il processo guida l’utente nell’installazione e nella configurazione iniziale di git, per cui è necessario comprendere le scelte da effettuare durante questo processo.
La prima schermata mostra la licenza da accettare.

La seconda schermata chiede all’utente di scegliere la cartella nella quale installare git. Si consiglia di accettare la cartella predefinita.

La terza schermata chiede all’utente di scegliere i componenti di git da installare. Si consiglia di lasciare tutti quelli già selezionati, assicurandosi di installare le voci “git Bash” e “git GUI” nel menù di explorer (il menù che appare cliccando con il tasto destro del mouse in un’area vuota), in modo tale da accedere velocemente al terminale da qualsiasi cartella.

La quarta schermata chiede all’utente di scegliere la voce del menu “Start” di Windows nella quale creare i collegamenti. La voce consigliata “Git” è una buona scelta.

La quinta schermata chiede all’utente di scegliere l’editor di testi da utilizzare. Si consiglia di installare Atom o Notepad++ e di selezionarlo in questo passo. L’editor “Vim” non è affatto semplice da utilizzare per un utente alle prime armi, Come indicato anche dal messaggio mostrato all’utente, si consiglia di installare e selezionare un editor moderno ed intuitivo.

La sesta schermata chiede all’utente di scegliere il nome iniziale del ramo di sviluppo da usare quando si crea un nuovo repository. Si anticipa che il ramo iniziale può avere nome “main” (usato anche da GitHub) o “master” (usato da GitLab, BitBucket, ecc..). In questo capitolo non sarà creato un nuovo repository, quindi si può lasciare l’opzione predefinita, anche se si vedrà spesso utilizzato il nome “main”.

La settima schermata chiede all’utente quali percorsi aggiungere alla variabile di sistema “PATH” (utilizzata per cercare i programmi da eseguire). Si consiglia di lasciare la scelta predefinita “command line and 3rd-party software”.

L’ottava schermata chiede all’utente quale componente utilizzare per validare i certificati. La libreria OpenSSL va bene per il singolo utente, mentre il componente di Windows “Secure Channel” è sicuramente più adatto in ambito aziendale, in contesti in cui i computer sono gestiti in maniera centralizzata dal sistemista.

La nona schermata chiede all’utente la codifica da utilizzare per il carattere di fine riga. Windows adotta la codifica “Carriage Return - Line Feed”, Linux, Unix e Mac adottano la codifica “Line Feed”. In generale il server che contiene il repository remoto adotta la codifica “Line Feed”.
Agli utenti Windows è consigliata la scelta della voce “Checkout Windows Style, commit Unix style line endings”.
Agli utenti Linux è consigliata la scelta della voce “Checkout as-is, commit Unix style line endings”.

La decima schermata chiede all’utente di scegliere il terminale da utilizzare quando si lavora a linea di comando. Si consiglia MinTTY, si può in qualsiasi caso lavorare anche con il terminale di Windows.

L’undicesima schermata chiede all’utente di scegliere la strategia di fusione quando si allinea il contenuto dal repository remoto al repository locale. Si consiglia di lasciare la scelta predefinita “fast forward on merge”.

La dodicesima schermata chiede all’utente di scegliere il componente per la gestione delle credenziali. Si consiglia di lasciare la scelta predefinita “Git Credential Manager”.

La tredicesima schermata chiede all’utente di scegliere se abilitare la cache memory (per migliorare le prestazioni) e se abilitare i link simbolici. Si consiglia di abilitare la cache memory e di ignorare i link simbolici.

La quattordicesima schermata chiede all’utente di abilitare funzionalità sperimentali. Si consiglia di non abilitare funzionalità che possono creare instabilità e falle di sicurezza.

A questo punto, l’installazione è terminata.
Concetto di controllo di versione
Per rendere l’idea di cosa significhi “sistema per il controllo di versione” (dall’inglese Version Control System), si può fare un’analogia con un’attività più vicina agli studenti: la realizzazione, da parte di un gruppo di studenti, di un progetto comune da consegnare ad uno o più insegnanti. Ogni studente prende in carico una parte specifica del progetto e si adopera per portarla a compimento.
Il progetto può essere la scrittura di un libro, la realizzazione di disegni tecnici, lo sviluppo di un sito web e tanto altro, e può essere diviso in varie fasi, al termine delle quali si può avere, eventualmente, un confronto con gli insegnanti interessati.
Ogni studente ha una propria area di lavoro, la scrivania di casa o la postazione nel laboratorio di informatica, sulla quale crea le varie bozze, effettua le varie prove ed un passo per volta svolge il compito giornaliero. Quando una piccola parte del lavoro è completa, ad esempio la scrittura di un capitolo del libro, la realizzazione di una pagina del sito web oppure il disegno tecnico relativo ad una stanza o ad un’ala del palazzo, allora ogni pagina è raccolta in un foglio plastificato. Le pagine nei fogli plastificati sono poi raccolte nel proprio quaderno ad anelli.
E’ importante tenere presente che il quaderno ad anelli ha una pagina di registro, in cui vengono annotate le operazioni effettuate, l’autore e la data. Quando lo studente sposta un lavoro nel proprio quaderno ad anelli, annota nome e data nella pagina di registro ed aggiunge l’operazione effettuata, l’aggiunta del nuovo capitolo, la cancellazione della pagina web o la modifica del disegno tecnico della stanza o dell’ala del palazzo.
Le pagine cancellate non vengono effettivamente cestinate, ma vengono annotate con una “X” rossa in un angolo (in modo tale che siano ancora leggibili) e spostate in coda al quaderno ad anelli (sempre raccolte nei loro foglio plastificati).
Le pagine da modificare vengono corrette con la matita, in modo da poter sempre cancellare tutto e tornare al lavoro originale. A modifica terminata, viene effettuata una copia completa (sempre raccolta in un foglio plastificato) in modo da poter sostituire quelle nel quaderno ad anelli. Le pagine corrette a matita non vengono cestinate, ma come per le pagine cancellate, vengono annotate con una “X” rossa e spostate in coda al quaderno ad anelli.
Anche per le pagine cancellate o modificate viene aggiornata la pagina di registro.
Questa gestione dei lavori, tramite un quaderno ad anelli con la pagina di registro e le modifiche/cancellazioni allegate in coda, realizza un primo rudimentale sistema di controllo di versione.
Grazie al controllo di versione realizzato, lo studente può decidere di ripristinare un capitolo che in precedenza aveva cancellato, semplicemente recuperandolo dalla coda del quaderno ad anelli. Allo stesso modo, può vedere dal registro il tempo impiegato per scrivere un nuovo capitolo o per realizzare una nuova pagina web. Ed ancora, può vedere tutte le modifiche apportate ad un certo disegno tecnico nel corso del tempo, recuperando tutte le correzioni effettuate dalla coda del quaderno ad anelli.
Controllo di versione centralizzato
Il quaderno ad anelli può essere condiviso tra tutti gli studenti che partecipano al progetto. Per poterlo condividere fisicamente, il quaderno ad anelli può essere lasciato nel laboratorio o nello studio di un insegnante.
Questo tipo di controllo di versione realizzato con il quaderno ad anelli comune è detto centralizzato.
I singoli studenti, quando completano un lavoro, aggiungendo, modificando o cancellando parti del progetto, sono tenuti a recarsi presso il laboratorio o lo studio dell’insegnante per poter aggiornare il quaderno comune, inserendo a registro le operazioni effettuate e, contestualmente, aggiungendo i nuovi lavori, spostando in coda le pagine cancellate ed effettuando una copia di quelle modificate (che poi sono spostate in coda).
Avere un quaderno ad anelli in comune permette agli studenti di lavorare in squadra, ma presenta alcuni svantaggi tipici di un sistema centralizzato:
- Se il quaderno ad anelli non è “raggiungibile”, ad esempio perché il laboratorio o lo studio dell’insegnante è chiuso per ferie o malattia, allora non è possibile consegnare un lavoro nè è possibile recuperare il lavoro di un altro studente;
- Se il quaderno ad anelli viene smarrito o distrutto, si perde tutto il lavoro;
- Se uno studente porta via per un certo periodo un capitolo o un progetto dal quaderno ad anelli, gli altri studenti non possono più accedervi, rimanendo di fatto bloccati.
Controllo di versione distribuito
Il quaderno ad anelli può essere personale, ogni studente che partecipa al progetto ha il suo, e quindi si può condividere un ulteriore quaderno ad anelli da conservare nello studio del professore universitario.
Il fatto che ogni studente ha il proprio quaderno ad anelli personale e che ce ne sia uno in comune realizza un sistema di controllo di versione distribuito.
Quando lo studente completa un lavoro, utilizza il proprio quaderno ad anelli personale sul quale annota nome e data nella pagina di registro ed aggiunge l’elenco di operazioni, indicando che ha inserito un nuovo capitolo, che ha cancellato una pagina web e che ne ha modificato un disegno tecnico.
I singoli studenti, periodicamente, si recano nello studio, per poter sincronizzare il proprio quaderno con il quaderno comune. Con il termine sincronizzare si intende che lo studente provvede ad effettuare sul quaderno comune tutte le modifiche che ha effettuato sul proprio e, viceversa, effettua sul quaderno proprio tutte le modifiche che sono state effettuate sul quaderno comune. Una volta sincronizzati, i due quaderni sono praticamente identici.
Nel dettaglio, uno studente che sincronizza il proprio quaderno con il quaderno comune, procede ad inserire sul registro del quaderno comune tutte le operazioni da lui effettuate (prendendole dal registro del quaderno personale) e, contestualmente, esegue queste operazioni sul quaderno comune, aggiungendo i nuovi lavori, spostando in coda le pagine da lui cancellate, effettuando una copia di quelle modificate che poi sposta in coda.
Allo stesso modo, effettua una copia dei lavori svolti dagli altri studenti, prendendoli dal quaderno ad anelli del professore, e la mette nel proprio quaderno ad anelli personale. Anche le pagine modificate e cancellate dagli altri studenti vengono copiate ed aggiunte in coda. Ed anche le operazioni di registro vengono aggiunte al proprio registro. In questo modo, i due quaderni ad anelli sono sincronizzati, di fatto sono identici.
Un secondo studente che si reca nello studio effettua le stesse operazioni, cosi come un terzo ed un quarto studente, per tutta la durata del progetto.
Il sistema distribuito comporta alcuni vantaggi:
- Se il quaderno ad anelli in comune non è “raggiungibile”, ad esempio perché il laboratorio o lo studio dell’insegnante è chiuso per ferie o malattia, lo studente può continuare a lavorare sulla propria copia del quaderno.
- Se il quaderno ad anelli in comune viene smarrito o distrutto, si può ricrearlo facendo la copia di un quaderno ad anelli di uno degli studenti (quello più aggiornato).
Modalità di lavoro con un sistema di controllo di versione distribuito
E’ possibile utilizzare molteplici modalità di lavoro per adattarsi alle diverse esigenze di sviluppo del progetto.
Si può utilizzare una modalità di lavoro con team leader, che si occupa di coordinare il lavoro del proprio team e quindi riportare il lavoro del team sul quaderno ad anelli del professore.
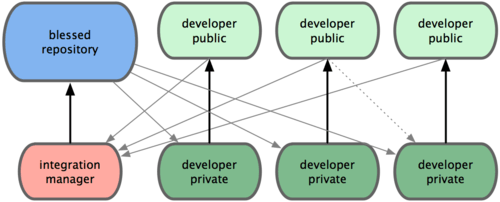
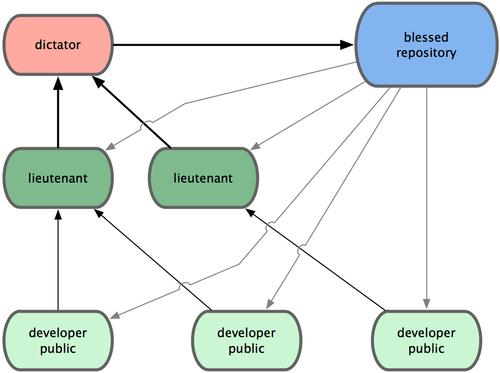
Si può utilizzare una modalità di lavoro detta “dittatore - tenente” in cui sono presenti diverse squadre di lavoro, ognuna con il proprio team leader (in questo caso detto “tenente”), ed un leader di progetto (detto “dittatore benevolo”) che coordina il lavoro dei vari “tenenti” e che si occupa di recuperare il lavoro dai quaderni ad anelli dei vari “tenenti” per comporre il progetto completo da condividere sul quaderno ad anelli condiviso. Tutti i team, poi, possono aggiornarsi sincronizzando i propri quaderni con questo quaderno condiviso. Questo metodo di lavoro, tra l’altro, è quello utilizzato per lo sviluppo del kernel Linux, in cui Linus Torvalds è il dittatore benevolo.
Rami di lavoro, conflitti e fusioni
Sia che si lavori con un sistema di controllo di versione centralizzato che con uno distribuito, si può verificare la situazione in cui un singolo lavoro debba proseguire su due o più direzioni.
Si immagini, ad esempio, che uno scrittore venga contattato da casa editoriale per la pubblicazione di un libro, partendo dalla sua bozza di romanzo, ed allo stesso tempo da un’azienda cinematografica per realizzare una serie TV, sempre partendo dalla sua bozza di romanzo. Può accadere che la casa editoriale e l’azienda cinematografica abbiano interessi diversi, magari indirizzando la scrittura verso due finali distinti, magari richiedendo allo scrittore avventure differenti per il protagonista.
Lo scrittore, lavorando ad un’unica opera complessiva sia per la serie TV, sia per il romanzo, rischia di apportare incongruenze o, addirittura, a non poter soddisfare entrambe le aziende. Dato che sono lavori differenti, lo scrittore deve seguire due filoni diversi, partendo dalla bozza di romanzo comune ad entrambe le opere.
Questi due filoni distinti sono i due rami di sviluppo del lavoro e possono essere rappresentati come un quaderno ad anelli contenente un cartoncino di separazione. Nel caso di un sistema distribuito, anche il quaderno ad anelli condiviso deve contenente un cartoncino di separazione. Tutti i fogli prima del cartoncino di separazione sono relativi alla pubblicazione del libro mentre quelli successivi sono relativi alla serie TV. Qualsiasi lavoro apportato alla serie TV non modifica minimamente la storia del libro e viceversa.
Per adattarsi alle diverse esigenze di sviluppo delle opere, è possibile creare un numero imprecisato di rami di sviluppo ed è possibile che più persone lavorino su uno stesso ramo di sviluppo.
Quando due persone modificano uno stesso ramo di sviluppo, uno stesso capitolo, allora si può verificare che le due versioni siano in conflitto tra loro, indicando, ad esempio, che il protagonista è presente in due posti diversi nella stessa avventura.
In questi casi, i due autori delle modifiche devono fonderle in una terza versione complessiva, prima di poterla includere nel quaderno ad anelli. Anche questa operazione di fusione viene indicata nel registro.
Un’altra situazione che si può verificare è che si voglia fondere due rami di sviluppo dell’opera in un unico ramo, ad esempio, per far si che due capitoli sviluppati su due rami differenti siano fusi in un unico capitolo. Anche in questo caso bisogna procedere all’operazione di fusione ed indicarla nella pagina di registro.
Concetti principali di Git
Partendo dall’analogia descritta in precedenza, possiamo descrivere i concetti principali sui quali si basa Git:
-
Gli oggetti non tracciati: sono tutti i fogli sui quali si lavora e che sono sparsi sulla scrivania di lavoro.
-
Gli oggetti tracciati: sono tutti i fogli dei lavori completati che sono raccolti nei loro fogli plastificati.
-
staging area o caching area: Rappresenta l’insieme dei lavori completati che sono raccolti nei loro fogli plastificati e che devono essere aggiunti nel quaderno ad anelli.
-
L’area di scorta, detta stashing area: E’ l’area nella quale vengono accantonati temporaneamente gli oggetti tracciati e non tracciati. Può essere rappresentata dai cassetti della scrivania. Quando il singolo studente deve mettere da parte i propri lavori o le proprie bozze di lavoro, le ripone in un cassetto, in modo da poter gestire un nuovo lavoro. Quando intende ritornare al precedente lavoro, lo recupera dal cassetto. Ci possono essere più cassetti per poter accantonare temporaneamente più lavori.
-
Il commit: E’ l’operazione effettuata dall’utente che permette di memorizzare nel sistema di controllo di versione le modifiche effettuate dall’utente. Ad ogni commit viene salvata una nuova versione del repository. Nell’analogia precedente è rappresentato dallo spostamento nel quaderno ad anelli dei lavori raccolti nei fogli plastificati, con annotazione del lavoro nella pagina di registro.
-
Le versioni: le operazioni di commit generano una nuova versione del lavoro svolto. Il lavoro precedente non viene cancellato, ma salvato, in modo da poter sempre tornare ad una versione precedente. L’ultima versione sul ramo di sviluppo sul quale lavora l’utente è detta HEAD.
-
Il repository locale: l’insieme delle operazioni di commit su cui Git lavora in locale. Sono conservate sul proprio computer, non è necessario collegarsi alla rete internet per lavorare. Nell’analogia precedente, ogni quaderno ad anelli di uno studente rappresenta un repository locale.
-
Il repository remoto: l’insieme di file versionati e tracciati su cui Git lavora in remoto. E’ ospitato sul server e quindi c’è bisogno del collegamento ad internet per ricevere il lavoro dei propri colleghi e per inviare il proprio lavoro. Nell’analogia precedente, è rappresentato dal quaderno ad anelli presente nello studio del professore.
-
La sincronizzazione: l’operazione di allineamento di due repository. In Git è divisa in due operazioni distinte:
- l’operazione di push consiste nell’inviare tutte le operazioni svolte nel repository locale in quello remoto. Nell’analogia precedente, è rappresentata dall’effettuare sul quaderno comune tutte le modifiche che sono state effettuate sul proprio quaderno;
- l’operazione di pull consiste nel recuperare tutte le operazioni svolte sul repository remoto per copiarle in quello locale. Nell’analogia precedente, è rappresentata dall’effettuare sul quaderno proprio tutte le modifiche che sono state effettuate sul quaderno comune dai vari studenti.
-
I rami di sviluppo, detti branches: E’ possibile seguire più rami di sviluppo dell’opera. Il ramo di sviluppo principale può essere chiamato trunk (come nel software SVN), master (come su GitLab) o main (come su GitHub). Gli altri rami di sviluppo sono detti branches. L’operazione che permette di unire due rami di sviluppo è la fusione, detta merge. Si rimanda al capitolo sui branches per una chiara spiegazione dei concetti relativi allo sviluppo su più rami.
-
La clonazione: l’operazione di creazione di un repository locale a partire da un repository remoto. Nell’analogia precedente, è rappresentata dal nuovo studente che si aggiunge al gruppo e che compra un nuovo quaderno ad anelli nel quale poi clona (copia) il contenuto del quaderno ad anelli del professore.
Creazione repository remoto su GitHub
GitHub è uno dei servizi online più famosi, permette la gestione di un repository Git tramite interfaccia web e semplifica l’interazione con l’utente.
L’utente, che completa il processo di registrazione su GitHub, accede alla pagina principale nella quale è presente l’elenco dei propri repository (nell’area sinistra) e (in alto a destra) l’icona del proprio account con relativo menù visualizzabile al click.

Accedendo alla pagina dei repository, l’utente può procedere alla creazione del proprio repository remoto, inserendo il nome del repository, la descrizione, la visibilità e indicando le opzioni relative la creazione del file README.md e la licenza da adottare per il progetto.
Se si vuole creare il repository relativo alla propria GitHub Page, allora il nome del repository deve obbligatoriamente essere username.github.io (ovviamente indicando il proprio username, ad esempio progetto-git.github.io).

La pagina web mostra il repository appena creato, contenente il file README.md.

L’indirizzo completo del repository su GitHub è visibile cliccando sul pulsante verde “code”:
 f
f
Creazione della chiave SSH
L’accesso al repository su GitHub è soggetto alla creazione di una coppia di chiavi pubblica/privata e relativa configurazione. E’ possibile creare la coppia di chiavi pubblica/privata SSH con il comando:
ssh-keygen -t ed25519 -f ~/.ssh/id_ed25519 -C "mail@mail.com"
Questo comando crea quindi il file con la chiave pubblica id_ed25519.pub ed il file con la chiave privata id_ed25519. Il file con la chiave pubblica contiene anche un hash della chiave, che di seguito sarà individuato dalla stringa key-hash.
Registrazione della chiave SSH su GitHub
L’utente può registrare la chiave di firma dei commit e di verifica accedendo alla sezione delle impostazioni nel menù utente:

A questo punto, nel menu laterale si clicca sulla voce “Chiavi SSH e GPG”:

Si può scegliere di aggiungere una chiave SSH cliccando sull’apposita voce:

Il nome da associare alla chiave è a scelta dell’utente, poi si deve scegliere se creare una chiave per firmare i commit oppure per verificarli. E nell’ultimo campo, si deve copiare la chiave pubblica, che è contenuta nel file id_ed25519.pub.

Si può ripetere lo stesso procedimento per aggiungere la stessa chiave per verificare i commit. Aggiunte le chiavi, il risultato lo si può visualizzare di seguito:

Per verificare che la connessione avvenga correttamente, ricordando che la chiave si trova nel file ~/.ssh/id_ed25519, si può utilizzare il comando seguente:
ssh -i "~/.ssh/id_ed25519" git@github.com
Hi progetto-git! You've successfully authenticated, but GitHub does not provide shell access.
Per verificare che la chiave di cui si è proprietari sia la stessa presente su GitHub, si può calcolare il codice hash “SHA256” della chiave che si possiede e confrontarlo con quello visualizzato su GitHub. Per recuperare le informazioni dalla chiave si utilizza il comando:
ssh-keygen -l -f ~/.ssh/id_ed25519
2048 SHA256: abacadaeaf1234567890 Comment for key xyz (ed25519)
^^^^ ^^^^^^^^^^^^^^^^^^^^^^^^ ^^^^^^^^^^ ^^^
|__ Size Fingerprint __| Comment __| Type __|
Creazione repository remoto su GitLab
GitLab è un altro servizio online famosissimo, permette la gestione di un repository Git tramite interfaccia web e semplifica l’interazione con l’utente.
GitLab permette la creazione di un repository remoto attraverso un’interfaccia grafica, in cui inserire il nome, la descrizione e la visibilità.

Creato il repository, viene fornito un URL per l’accesso e la clonazione dello stesso, come in figura:

L’indirizzo completo del repository su GitLab, non completamente riportato nell’immagine, è il seguente:
https://gitlab.com/codingepaduli/gitmergetutorial.git
Clonazione repository
Una volta creato il repository remoto, bisogna prendere nota dell’indirizzo web dello stesso per poi procedere alla clonazione. E’ importante indicare anche la chiave SSH da utilizzare, che tipicamente si trova nella cartella ~/.ssh/id_ed25519. Il comando di clonazione è il seguente comando:
git clone git@github.com:progetto-git/progetto-git.github.io.git --config core.sshCommand="ssh -i ~/.ssh/id_ed25519"
Si può verificare che il repository locale ha un riferimento al repository remoto, accedendo alla cartella creata ed utilizzando, al suo interno, il comando:
git remote -v
Gestione del repository
Prima configurazione del repository
Git ha 3 livelli di configurazione:
- configurazione di sistema, su linux si trova in
/etc/gitconfig, su Windows si trova in\Git\mingw64\etc\gitconfig; - configurazione globale (o utente), si trova nella cartella Home nel file
.gitconfig); - configurazione locale al repository, si trova nella cartella
.git;
Per verificare le configurazioni presenti ad ogni livello, si usano i seguenti comandi:
git config --system --list
git config --global --list
git config --local --list
E’ consigliabile utilizzare una configurazione per ogni repository, anche se si può scegliere una configurazione comune per l’utente e poi sovrascrivere le sole proprietà necessarie ai singoli repository. E’ buona norma evitare di usare la configurazione di sistema, disabilitandola a livello globale attraverso il comando:
git config --global user.useConfigOnly true
Per configurare le credenziali del singolo repository, si usano i comandi seguenti:
git config --local user.name "User"
git config --local user.email "user@user.com"
Altra operazione generalmente consigliata è l’impostazione del carattere di fine riga, dato che su Linux e Mac il carattere di fine riga (INVIO) è LF (line feed) mentre su Windows il carattere di fine riga (INVIO) è CR + LF (carriage return + line feed).
Questa differenza di caratteri porta ad avere confusione quando un file è modificato sia da utenti Mac/Linux sia da utenti Windows. Molti editors su Windows sostituiscono i caratteri di fine riga LF con i caratteri CR + LF, oppure lasciano gli LF ma inseriscono CR + LF quando si preme invio.
Una macchina windows deve quindi essere configurata per la conversione automatica da LF a CR + LF e viceversa:
git config --local core.autocrlf true
Una macchina Linux invece deve essere abilitata per la correzione automatica di tutti i file che arrivano dal repository trasformando i caratteri CR + LF con il carattere LF:
git config --local core.autocrlf input
Altre opzioni di configurazione utili
Per rilevare in tempo la corruzione del repository:
git config --local transfer.fsckobjects true
git config --local fetch.fsckobjects true
git config --local receive.fsckObjects true
Se necessario, si può scegliere di non ignorare la differenza tra caratteri minuscoli e maiuscoli nei nomi dei file, con il comando:
git config --local core.ignorecase false
Se si vuole memorizzare le credenziali, può essere utile il comando:
git config --local credential.helper store
Quando git chiede quale tecnica usare per sincronizzare il repository. Si consiglia la seguente:
git config --local pull.rebase false
Per configurare l’editor e gli strumenti per visualizzare le differenze si possono usare i seguenti comandi:
git config --local core.editor "micro"
git config --local diff.algorithm histogram
git config --local diff.tool "meld"
git config --local difftool.prompt false
git config --local merge.tool "meld"
git config --local mergetool.prompt false
Configurazione chiave SSH per firma e verifica
Creata la coppia di chiavi pubblica/privata e registrata su GitHub, è possibile utilizzare queste chiavi anche per firmare e verificare i commit, configurando il client locale con i seguenti comandi:
git config --local commit.gpgsign true
git config --local gpg.format ssh
git config --local user.signingkey "$HOME/.ssh/id_ed25519.pub"
git config --local gpg.ssh.allowedSignersFile "$HOME/.ssh/allowed_signers"
git config --local core.sshCommand "/usr/bin/ssh -i $HOME/.ssh/id_ed25519"
con il file allowed_signers composto dalla stringa:
mail algoritmo-ssh #key-hash
Ad esempio, la chiave SSH creata in precedenza con l’algoritmo ssh-ed25519 corrisponde alla stringa:
mail@mail.com ssh-ed25519 #key-hash
Staging area e commit
Per creare una nuova versione del repository locale e poi sincronizzarla con il repository remoto, si può partire dalla creazione di tre file, file1.txt, file2.txt e file3.txt, in modo da seguire le varie operazioni.
Creati i tre file, si può aggiungere il primo file alla staging area (detta anche “caching area”), utilizzando il comando:
git add file1.txt
Per visualizzare ora lo stato dei file, si utilizza il comando:
git status
L’output è il seguente:
Sul branch main
Il tuo branch è aggiornato rispetto a 'origin/main'.
Modifiche di cui verrà eseguito il commit:
(usa "git restore --staged <file>..." per rimuovere gli elementi dall'area di staging)
nuovo file: file1.txt
File non tracciati:
(usa "git add <file>..." per includere l'elemento fra quelli di cui verrà eseguito il commit)
file2.txt
file3.txt
Si nota che il file file1.txt risulta tracciato e pronto per il commit, mentre i file file2.txt e file3.txt risultano non tracciati (“untracked”).
Effettuando ulteriori modifiche al file file1.txt, questo risulta modificato, come si nota visualizzando lo stato dei file attraverso il comando:
git status
L’output è il seguente:
Sul branch main
Il tuo branch è aggiornato rispetto a 'origin/main'.
Modifiche di cui verrà eseguito il commit:
(usa "git restore --staged <file>..." per rimuovere gli elementi dall'area di staging)
nuovo file: file1.txt
Modifiche non nell'area di staging per il commit:
(usa "git add <file>..." per aggiornare gli elementi di cui sarà eseguito il commit)
(usa "git restore <file>..." per scartare le modifiche nella directory di lavoro)
modificato: file1.txt
File non tracciati:
(usa "git add <file>..." per includere l'elemento fra quelli di cui verrà eseguito il commit)
file2.txt
file3.txt
I file possono avere 4 stati:
- untracked: non tracciati da Git;
- staged: tracciati e pronti ad essere inclusi in un commit (“to be committed”);
- modified: modificati rispetto all’ultimo commit;
- unmodified: non modificati rispetto all’ultimo commit;
Prima di poter effettuare il commit del file file1.txt, questo deve essere nuovamente aggiunto all’area di “staging”. I comandi per l’aggiunta e per il commit sono i seguenti:
git add file1.txt
git commit -m "Primo commit"
A questo punto il commit è stato completato ed è stata salvata la nuova versione del repository locale. Per visualizzare la lista di commit e relative versioni del repository locale, si utilizza il comando:
git log --pretty=format:"%h %s" --graph
Questo comando permetta anche di avere una vista grafica delle varie versioni del repository locale.
E’ utile sottolineare che HEAD è solo un riferimento al commit (e quindi alla versione) del ramo di sviluppo su cui si lavora.
Quando si scaricano le ultime versioni da repository remoto nel repository locale, il riferimento HEAD viene aggiornato all’ultimo commit scaricato da remoto, sempre per il ramo di sviluppo su cui si sta lavorando. Quando invece si effettua un commit in locale, il riferimento HEAD viene aggiornato a questo commit.
Sincronizzazione
Effettuati i vari commit sul repository locale, ci si trova nella situazione in cui il repository locale si trova in una versione più avanzata rispetto al repository remoto (che è stato clonato).
Se si ha un repository locale ma il repository remoto non è stato creato, allora non si ha possibilità di sincronizzazione. Se ci si vuole registrare ad un servizio online e poi collegare il repository locale a quello remoto, allora si può consultare la sezione sulle origini remote per effettuare il collegamento.
Per sincronizzare il lavoro (tutti i commit sul repository locale) con il repository remoto, si utilizza il comando:
git push origin main
L’operazione di push invia tutti i commit (che sono stati eseguiti sul repository locale) al repository remoto.
Per effettuare l’operazione inversa, cioè per ricevere nel repository locale tutti i commit dal repository remoto (eseguiti dallo stesso utente attraverso computer differenti o eseguiti da altri utenti), si utilizza il comando:
git pull origin main
Gestione dei file nella staging area
Può capitare di aggiungere per errore un file alla staging area, per cui lo si vuole togliere, senza però cancellarlo e perdere il contenuto, ma lasciandolo intatto nella cartella in cui si trova. Il comando da utilizzare è:
git restore --staged file
Se si vuole ripristinare il file allo stato dell’ultimo commit, allora bisogna prima toglierlo dalla staging area e poi cancellare le modifiche, utilizzando i comandi:
git restore --staged file
git restore file
Se si vuole cancellare tutti i file e cartelle che non sono tracciati, si utilizza il comando:
git clean -fd
Per cancellare la cache, in caso di “malfunzionamenti”, si usa:
git gc --auto
Stashing area (conservazione temporanea)
Quando si stanno applicando modifiche ai file e si deve interrompere l’attività per dare priorità ad altri lavori, si possono spostare i file modificati in un’area di conservazione temporanea: la stashing area.
Per spostare tutti i file modificati e i file non tracciati in un’area temporanea si utilizza il comando:
git stash
Per visualizzare la lista di aree temporanee disponibili, si utilizza il comando:
git stash list
Questo comando elenca tutte le aree temporanee (che possono essere più di una) identificandole con un numero. Questo numero è utilizzato per identificare l’area temporanea.
Per riportare nella staging area i file precedentemente spostati in stashing area, si utilizza il comando:
git stash apply stash@{0}
dove il numero zero è l’indice dell’area temporanea dalla quale prendere i file.
Per eliminare un’area temporanea, si utilizza il comando:
git stash drop stash@{0}
dove il numero zero è l’indice dell’area temporanea da cancellare.
Reset delle operazioni
In alcuni casi può essere necessario ripristinare il repository locale allo stato del repository remoto. Questo può essere necessario in alcuni casi:
- In caso venga svolta l’operazione di
git pullma sono presenti dei cambiamenti in locale, ci si può trovare il mio stato “divergente”, come indicato dal messaggio “your branch and ‘origin/master’ have diverged and have 1 and 83 different commits each, respectively”; - In caso venga svolta l’operazione di
git checkoutci si può trovare in uno stato di “detached head”, come indicato dal messaggio “You are in ‘detached HEAD’ state”
Sia per invertire la “divergenza”, sia per tornare indietro dello stato di “detached HEAD”, accettando in entrambi i casi di perdere tutti i cambiamenti fatti sul repository locale, si può utilizzare il comando:
git reset –hard origin/master
Lavorare con più origini remote
Quando si effettua la clonazione di un repository, Git crea un riferimento a questo repository remoto, chiamato origin:
E’ però possibile utilizzate più repository remoti, semplicemente aggiungendo un riferimento remoto, di seguito chiamato gitlab, al repository locale:
git remote add gitlab https://gitlab.com/progetto-git/progetto-git.git
Per visualizzare i repository remoti, si può utilizzare il comando:
git remote -v
L’output mostrato è il seguente:
gitlab https://gitlab.com/progetto-git/progetto-git.git (fetch)
gitlab https://gitlab.com/progetto-git/progetto-git.git (push)
origin git@github.com:progetto-git/progetto-git.github.io.git (fetch)
origin git@github.com:progetto-git/progetto-git.github.io.git (push)
Come si nota, i riferimenti remoti per le operazioni di invio e ricezione dati (“push” e “fetch”) possono essere differenti.
Per sincronizzare il ramo di sviluppo principale main del repository remoto con il repository locale, si effettuano le classiche operazioni di push e pull, facendo però attenzione ad indicare l’origine gitlab appena creata.
git push gitlab main
git pull gitlab main
Si nota che in questo caso viene sincronizzato il ramo di sviluppo principale main.
Gestione di più rami di sviluppo
Modalità di lavoro con più rami
Il repository principale ha un ramo di sviluppo principale chiamato main o master, ma sul repository possono essere creati anche altri rami di sviluppo chiamati branches, che costituiscono la modalità comune di lavoro con Git.
Tipicamente sul repository vengono creati diversi branches (rami di sviluppo) per le diverse funzionalità da sviluppare, e su ogni singolo branch (ramo) viene sviluppata una singola funzionalità da parte di uno o più sviluppatori del team.
Gli sviluppatori che lavorano su un singolo branch creano quindi la prima versione della funzionalità da sviluppare effettuando il primo commit, poi gli sviluppi proseguono e viene creata la seconda versione con un secondo commit, poi la terza versione a cui corrisponde un terzo commit, e cosi via.
Quando la funzionalità viene completata, questo singolo ramo di sviluppo può essere fuso con il ramo di sviluppo principale.
Sul ramo principale vengono quindi fusi tutti i diversi rami di sviluppo e quindi di volta in volta le varie funzionalità vengono aggiunte al ramo di sviluppo principale main.
Volendo fare un’analogia, si può immaginare la scrittura di una trilogia di libri, e quindi ogni singolo libro viene scritto in un ramo separato. Il ramo principale alla fine conterrà tutti e tre i volumi.
Volendo fare una seconda analogia, si può immaginare che in uno dei libri della trilogia i personaggi principali si separino, vivendo storie indipendenti, e quindi nel ramo di sviluppo del singolo libro si creano diversi rami in cui si scrivono le storie dei diversi personaggi. Una volta che la storia di un personaggio è completa, il ramo di sviluppo del singolo personaggio viene fuso con il ramo di sviluppo del libro della trilogia.
Creazione e gestione dei rami
Per creare un nuovo ramo con nome git-merge si utilizza il comando:
git branch git-merge
Per visualizzare l’elenco dei rami disponibili si utilizza il comando:
git branch --list
Per spostarsi sul ramo “git-merge” appena creato, si utilizza il comando:
git switch git-merge
Esiste anche l’opzione per creare e spostarsi sul nuovo ramo, utilizzando il comando:
git switch -c git-merge
Quando si effettua il passaggio da un ramo all’altro, lo sviluppatore dovrebbe accertarsi di lasciare il ramo pulito.
Se nella cartella di lavoro ci sono file tracciati dei quali non è stato effettuato il commit oppure file non tracciati, quando si effettua lo switch, questi file vengono comunque lasciati nella cartella di lavoro, creando un’incongruenza, dato che non appartengono al ramo selezionato.
I comandi di aggiunta e commit sono quelli già visti in precedenza, solo che questa volta il commit viene legato al nuovo ramo. Ad esempio:
git add file.txt
git commit -m "aggiunto file.txt"
Per visualizzare la lista di commit nei vari branches del repository, si è gia visto di utilizzare il comando di log con grafico:
git log --pretty=format:"%h %s" --graph
Sincronizzazione dei rami tra locale e remoto
Quando si crea un branch in locale, si deve ricordare che il repository remoto non ne possiede una copia, e quindi un’azione di sincronizzazione genera errore. Per indicare di creare un branch anche in remoto ed al contempo sincronizzare il branch, si utilizza il comando:
git push --set-upstream origin git-merge
In remoto è possibile che siano stati creati o cancellati branch, quindi è necessario sincronizzare repository locale e remoto per poter avere disponibili tutti i branch.
Per poter scaricare tutti i branch, si utilizza il comando:
git fetch --all
Per poter pulire i branch locali, cancellando quelli che anche in remoto sono stati rimossi, si utilizza il comando:
git fetch --prune
Merge dei rami in modalità a linea di comando
Quando si vuole effettuare la fusione del ramo “git-merge” con il ramo “main”, da linea di comando bisogna spostarsi sul ramo di sviluppo principale main.
git switch main
Effettuato ciò, si può effettuare la fusione del ramo “git-merge”, eseguendo il comando:
git merge git-merge
L’output indica che l’operazione è stata eseguita:
Merge made by the 'recursive' strategy.
content/coding/tools/Git.md | 84 +++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++++----
coding/tools/Git.md | Bin 39000 -> 39569 bytes
2 files changed, 80 insertions(+), 4 deletions(-)
E’ possibile verificare che i 2 branch sono stati fusi in un unico branch, attraverso il comando:
git log --pretty=format:"%h %s" --graph
L’output indica in forma grafica che i rami di sviluppo sono stati fusi e che effettivamente confluiscono in un unico ramo:
* b21a312 Merge pull request #1
|\
| * ae55ada Updated posts about tools
|/
Merge dei rami in modalità grafica
Quando si vuole effettuare la fusione del ramo “git-merge” con il ramo “master”, si può utilizzare lo strumento grafico messo a disposizione dai servizi online.
I passi consistono nel creare una “New pull request”, cliccando sul relativo pulsante:

Il servizio online mostra una coppia di branch da selezionare per la fusione:

L’utente deve selezionare come base il ramo che deve contenere la modifica, in questo caso il ramo principale (master), e, come ramo da confrontare, il ramo “git-merge” del quale effettuare la fusione. Appena viene selezionato, comparirà la seguente finestra:

La finestra indica, attraverso la scritta “Able to merge”, che è possibile effettuare la fusione dei due rami in maniera automatica. A questo punto bisogna quindi solo confermare la creazione della pull request, cliccando sull’apposito tasto.
L’utente può opzionalmente aggiungere un commento prima di completare l’operazione:

Ad operazione completata, nella sezione “Pull request” si può verificare che la nuova pull request è stata creata.

Creata la pull request, si deve effettuare l’operazione di “merge della pull request”. Per far ciò, l’utente deve selezionare la pull request nell’elenco precedente e quindi può visualizzare il dettaglio della pull request creata. Tra le altre cose, è descritto che il branch non ha conflitti e quindi l’operazione di fusione può essere effettuata automaticamente confermando l’operazione di “merge della pull request”..

All’utente è richiesto l’inserimento di un commento opzionale e di completare l’operazione:

Completata l’operazione, la pull request risulta correttamente fusa nel ramo di sviluppo indicato.

Sottomoduli
Il progetto che si sta sviluppando può dipendere da altri progetti. Queste dipendenze nella terminologia di Git sono dette sottomoduli.
Dato che non è pratico copiare ed incollare questi sottomoduli nelle cartelle di progetto e poi aggiornarli o tenere traccia delle modifiche apportate, Git si occupa di gestire il tutto, memorizzando per ogni dipendenza l’URL del corrispondente repository GIT.
Per aggiungere una dipendenza al progetto, si utilizza il comando:
git submodule add "Git repository URL"
Per cancellare una dipendenza al progetto, si utilizza il comando:
$ git rm -f childmodule
I comandi precedenti creano o modificano il file .gitmodules locato nella cartella di progetto.
Per scaricare il progetto con tutte le sue dipendenze, si utilizza il comando:
git clone --recursive "Git repository URL"
Se si ha gia il progetto, ma si devono scaricare le dipendenze necessarie, si utilizza il comando:
git submodule update --init --recursive
Per aggiornare tutte le dipendenze si utilizza il comando:
git submodule update --remote
Aree di lavoro (worktree)
E’ già stato menzionato in precedenza che quando si effettua il passaggio da un ramo all’altro, lo sviluppatore dovrebbe accertarsi di lasciare il ramo pulito, al fine di evitare incongruenze dovute a file che non appartengono al ramo su cui si passa.
Ci sono situazioni in cui sopravviene l’urgenza di modificare un ramo mentre si sta lavorando su un altro ramo alla modifica di molti file. In questa situazione, effettuare un operazione di commit di un lavoro incompleto (e magari non funzionante) è fuori questione. Il passaggio al ramo che necessita la correzione non è assolutamente consigliato, perchè tutti i file modificati verrebbero spostati nel ramo nel quale ci si sposta, creando incongruenza. Si potrebbe pensare di conservare i file modificati nella stashing area, ma esiste un alternativa.
Esiste la possibilità di creare una copia del ramo desiderato in una cartella differente e lavorare in quella cartella, lasciando la cartella attuale inalterata. Il comando git worktree si occupa di creare le varie copie, permettendo di avere più cartelle in contemporanea, ognuna su un ramo differente o con uno stato differente.
E’ da tenere a mente che queste copie possono essere cancellate automaticamente dopo un certo tempo, quindi si consiglia di leggere la documentazione per trattare copie che si vuol conservare per lunghi periodi.
Ad esempio, per creare nella cartella “..progetto-git-worktree” uno spazio di lavoro “progetto-worktree” partendo dal ramo “main”, si utilizza il comando seguente:
git worktree add -b progetto-worktree ../progetto-git-worktree main
A questo punto, si possono visualizzare gli spazi di lavoro con il seguente comando:
git worktree list
/SVN/progetto-git.github.io d8c1b27 [main]
/SVN/progetto-git-worktree 1c0b453 [progetto-worktree]
Si sottolinea che “progetto-worktree” è il nome dello spazio di lavoro ma è anche il ramo “progetto-worktree”, come si può vedere dal comando seguente:
git branch --list
git-merge
* main
+ progetto-worktree
La situazione consigliata è quella di avere una sola copia per ramo, anche se è possibile forzare questo meccanismo. Se si prova ad effettuare lo switch dal ramo “main” verso il ramo “progetto-worktree” si ottiene il seguente messaggio di errore:
git switch progetto-worktree
fatal: Il checkout di 'progetto-worktree' è già stato eseguito in '/SVN/progetto-git-worktree'
Una volta che il lavoro è stato svolto sul ramo “progetto-worktree”, si consiglia di rimuoverlo e di pulire i riferimenti con i comandi
git worktree remove progetto-worktree
git worktree prune
Nota: in caso di errori, si può provare ad indicare il percorso completo della cartella:
git worktree remove /SVN/progetto-git-worktree
git worktree prune
Contribuire ad altri progetti
Git permette di contribuire ai progetti esterni (di altri sviluppatori, anche sconosciuti) inviando sui loro repository delle pull request contenenti le proprie modifiche.
Per questioni di sicurezza, però, non è possibile inviare lavoro su un repository che non è il proprio. Dato che si vuole apportare una modifica ad un repository di cui non si possiede la titolarità, è necessaria un’operazione preliminare: la fork. Con questa operazione, si effettua una copia del repository dello sviluppatore e di questa copia si è titolari.
Per contribuire al repository dell’altro sviluppatore si effettuata la fork e la clonazione del repository, sul quale si apporteranno le modifiche, e quindi si crea una pull request tra il proprio repository ed il repository dell’altro sviluppatore.
L’altro sviluppatore può quindi accettare (ed effettuare l’operazione di merge della pull request ricevuta) oppure può scegliere di rifiutare di includere le modifiche ricevute.
Approfondimenti
L’introduzione a git non parla delle molteplici funzionalità avanzate che possono essere però approfondite nelle varie guide e libri, tra i quali si segnala:
La serie di articoli su Mokabyte:
- http://www.mokabyte.it/2016/09/git-1/;
- http://www.mokabyte.it/2016/10/git-2/;
- http://www.mokabyte.it/2017/01/git-3/;
- http://www.mokabyte.it/2017/02/git-4/;
- http://www.mokabyte.it/2017/04/git-5/;
- http://www.mokabyte.it/2017/05/git-6/;
- http://www.mokabyte.it/2017/07/git-7/;
- http://www.mokabyte.it/2017/10/git-8/;
- http://www.mokabyte.it/2017/12/git-9/;
- http://www.mokabyte.it/2018/01/git-10/;
Il libro su git: https://www.git-scm.com/book/en/v2.
Riferimenti
How to correct mistakes in Git: How to correct mistakes in Git
GitHub’s free, web-based editor: GitHub’s free, web-based editor that runs entirely in your browser